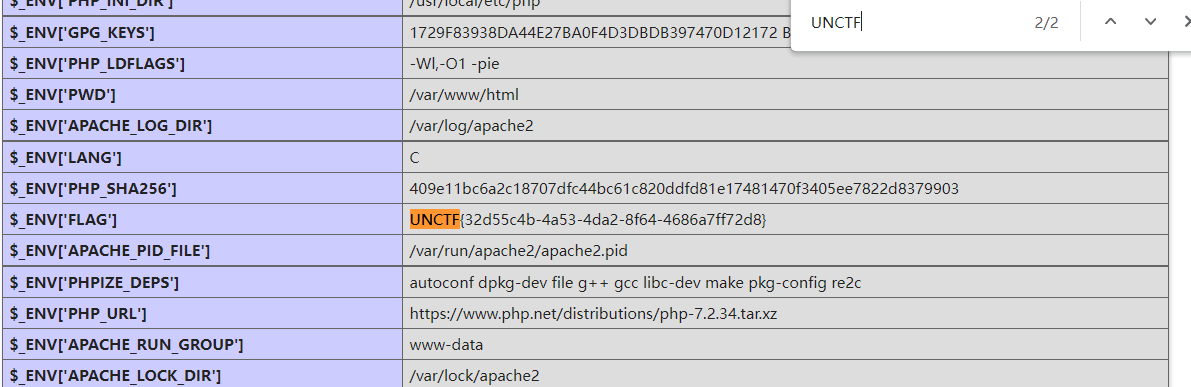
1'; alter table admin.haha rename to admin.haha1;alter table ctftraining.FLAG_TABLE rename to admin.haha;alter table admin.haha change FLAG_COLUMN id varchar(128);#
f = open('C:\\Users\\LiangMaxwell\\Downloads\\zhiyin\\lanqiu.jpg','wb').write(open("C:\\Users\\LiangMaxwell\\Downloads\\zhiyin\\qiulan.jpg",'rb').read()[::-1])
from hashlib import md5 hashlist=[ "8FA14CDD754F91CC6554C9E71929CCE7", "2DB95E8E1A9267B7A1188556B2013B33", "0CC175B9C0F1B6A831C399E269772661", "B2F5FF47436671B6E533D8DC3614845D", "F95B70FDC3088560732A5AC135644506", "F1290186A5D0B1CEAB27F4E77C0C5D68", "E1671797C52E15F763380B45E841EC32", "2DB95E8E1A9267B7A1188556B2013B33", "4A8A08F09D37B73795649038408B5F33", "D95679752134A2D9EB61DBD7B91C4BCC", "6F8F57715090DA2632453988D9A1501B", "E1671797C52E15F763380B45E841EC32", "B14A7B8059D9C055954C92674CE60032", "E358EFA489F58062F10DD7316B65649E", "D95679752134A2D9EB61DBD7B91C4BCC", "B14A7B8059D9C055954C92674CE60032", "6F8F57715090DA2632453988D9A1501B", "865C0C0B4AB0E063E5CAA3387C1A8741", "03C7C0ACE395D80182DB07AE2C30F034", "4A8A08F09D37B73795649038408B5F33", "CBB184DD8E05C9709E5DCAEDAA0495CF" ] dic="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789}{" flag ="" for i in hashlist: print(i) for x in dic: if md5(x.encode()).hexdigest() == i.lower(): # print(x)
flag += x
print(flag) #flag{welcometomisc}
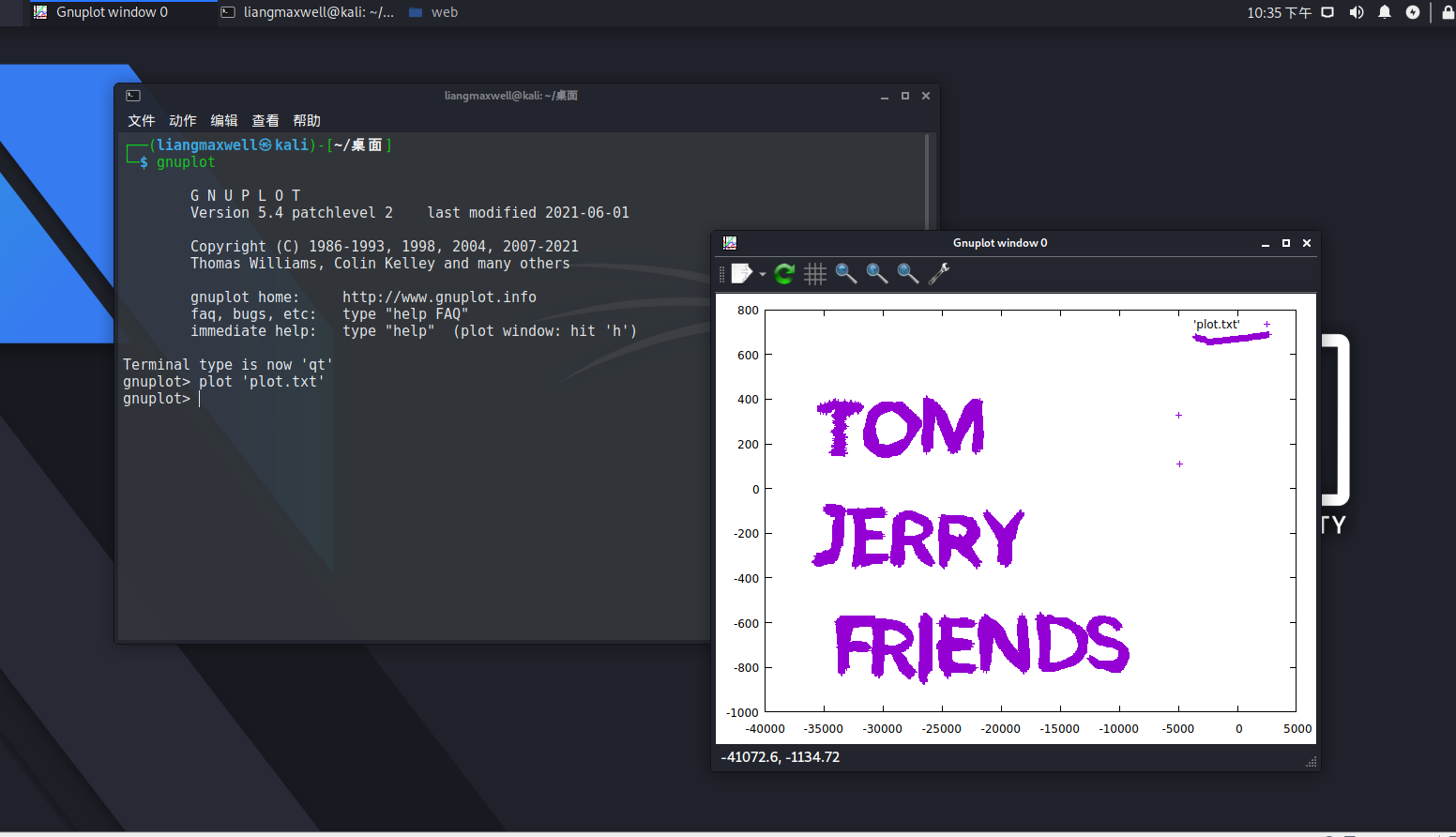
MY PICTURE
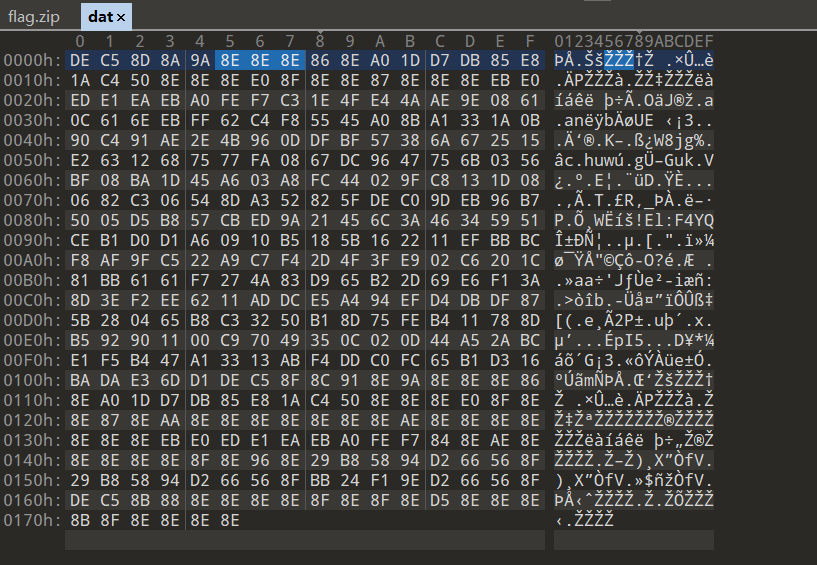
解压之后是一个没后缀的zip,再次解压之后得到一个dat文件和一个flag.png
dat文件打开后发现很多的8E字节,便猜测是异或了8E,再次异或回来后得到一个压缩包
解压后得到加密时使用的脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
from PIL import Image as im
flag = im.open('flag.jpg','r') l,h=flag.size puzzle=im.new('RGB',(h,l)) print(puzzle) for i inrange(l): for j inrange(h): r,g,b=flag.getpixel((i,j)) r=r^g g=g^b b=b^r puzzle.putpixel(((i*787+j)//1200,(i*787+j)%1200),(b,g,r)) puzzle.save('flag.png') flag.close() puzzle.close()
逆着改出来解密脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14
from PIL import Image as im
flag = im.open('C:\\Users\\LiangMaxwell\\Downloads\\Picture\\flag.png','r') l,h=flag.size ans=im.new('RGB',(h,l)) for i inrange(l): for j inrange(h): r,g,b=flag.getpixel((i,j)) b = b ^ r g = g ^ b r = r ^ g ans.putpixel(((i*1200+j)//787,(i*1200+j)%787),(b,g,r)) ans.save('C:\\Users\\LiangMaxwell\\Downloads\\Picture\\realflag.png')
defconvert_to_signed_char(c): if c > 127: return (256-c) * (-1) else: return c
# Transform to actual data lines data_lines = (wrap(line.strip(), 2) for line inopen("out.txt").readlines()) data_packets = [] for l in data_lines: data_packets.append([convert_to_signed_char(int(a, 16)) for a in l])
# Remove trailing data # data_packets = data_packets[:-1400]
# Write to file withopen("plot.txt", "w") as f: x = 0 y = 0 for packet in data_packets: try: x += packet[1] * 20# Scale-up X-axis y -= packet[2] # Invert Y-axis if packet[0] == 1: f.write(f"{x}{y}\n") except: pass
nums = [] keys = open('usbdata.txt') for line in keys: iflen(line) != 17: continue nums.append(line[0:2] + line[4:6]) keys.close() output = "" for n in nums: if n[2:4] == "00": continue
if n[2:4] in normalKeys: if n[0:2] == "02": output += shiftKeys[n[2:4]] else: output += normalKeys[n[2:4]] else: output += '' print('output :' + output)
import binascii defget_base64_diff_value(s1, s2): base64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/' res = 0 for i in xrange(len(s2)): if s1[i] != s2[i]: returnabs(base64chars.index(s1[i]) - base64chars.index(s2[i])) return res
defsolve_stego(): withopen('C:\\Users\\LiangMaxwell\\Downloads\\src\\flag.txt', 'rb') as f: file_lines = f.readlines() bin_str = '' for line in file_lines: steg_line = line.replace('\n', '') norm_line = line.replace('\n', '').decode('base64').encode('base64').replace('\n', '') diff = get_base64_diff_value(steg_line, norm_line) # print diff pads_num = steg_line.count('=') if diff: bin_str += bin(diff)[2:].zfill(pads_num * 2) else: bin_str += '0' * pads_num * 2
# print bin_str
return bin_str # print goflag(bin_str)
defgoflag(bin_str): res_str = '' for i in xrange(0, len(bin_str), 8): res_str += chr(int(bin_str[i:i + 8], 2))
return res_str
if __name__ == '__main__': bins = solve_stego() x = goflag(bins) print x
# 进度条 defprogress(percent=0, width=40): left = width * percent // 95 right = width - left print('\r[', '#' * left, ' ' * right, ']', f' {percent:.0f}%', sep='', end='', flush=True)
# 一位字节 defcrc1(strs, dic): strs = hex(int(strs, 16)) rs = '' for i in dic: s = i ifhex(binascii.crc32(s.encode())) == strs: rs += s print(strs + ' : ' + s) return rs
# 两位字节 defcrc2(strs, dic): strs = hex(int(strs, 16)) rs = '' for i in dic: for j in dic: s = i + j ifhex(binascii.crc32(s.encode())) == strs: rs += s print(strs + ' : ' + s) return rs
# 三位字节 defcrc3(strs, dic): strs = hex(int(strs, 16)) rs = '' for i in dic: for j in dic: for k in dic: s = i + j + k ifhex(binascii.crc32(s.encode())) == strs: rs += s print(strs + ' : ' + s) return rs
# 四位字节 defcrc4(strs, dic): strs = hex(int(strs, 16)) rs = '' it = 1 for i in dic: for j in dic: for k in dic: for m in dic: s = i + j + k + m ifhex(binascii.crc32(s.encode())) == strs: rs += s print() print(strs + ' : ' + s) print('\n') progress(it) sleep(0.1) it += 1 return rs
# 五位字节 defcrc5(strs, dic): strs = hex(int(strs, 16)) rs = '' it = 1 for i in dic: progress(it) for j in dic: for k in dic: for m in dic: for n in dic: s = i + j + k + m + n ifhex(binascii.crc32(s.encode())) == strs: rs += s print() print(strs + ' : ' + s) print('\n') sleep(0.1) it += 1 return rs
# 计算碰撞 crc defCrackCrc(crclist, length): print() print("正在计算...") print() dic = ''' !"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\\]^_`abcdefghijklmnopqrstuvwxyz{|}~'''# 碰撞需要的字符字典 dic = dic[::-1] text = '' for i in crclist: if length == '1': text += crc1(i, dic) if length == '2': text += crc2(i, dic) if length == '3': text += crc3(i, dic) if length == '4': text += crc4(i, dic) if length == '5': text += crc5(i, dic) print('\n') if text == '': print("碰撞失败,无结果") exit() print("字符顺序组合:", end=' ') print() print(text) print() input("回车确认结束程序...")
dic="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789}{" flag ="" for i in hashlist: print(i) for x in dic: if md5(x.encode()).hexdigest() == i: # print(x) flag += x
dic="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789}{" flag ="" for i in realmd5: print(i) iflen(i) == 31: i = '0' + i for x in dic: if md5(x.encode()).hexdigest() == i: # print(x) flag += x print(flag)
dddd
一眼摩斯
caesar
用BASE64的表进行凯撒加密,直接用最常见的BASE表就行,没有用自己打乱的表是出题人的仁慈
1 2 3 4 5 6 7 8 9 10 11 12
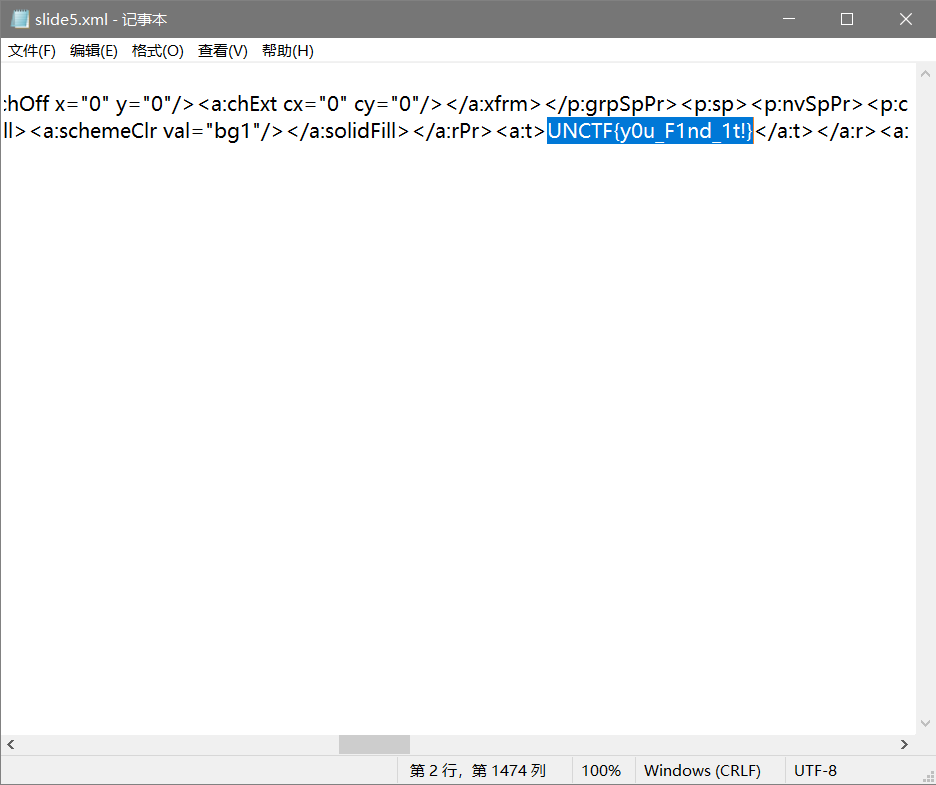
#B6vAy{dhd_AOiZ_KiMyLYLUa_JlL/HY} #UNCTF{w0w_Th1s_d1fFerentc_4eSar} puzzle = "B6vAydhdAOiZKiMyLYLUaJlL/HY"#暂时去掉表里没有的字符 charset = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/" flag = "" for i in puzzle: print(i) local = charset.index(i) ans = charset[((local+19)%64)] flag+=ans
from Crypto.Util.number import * from secret import flag import libnum
flag = "UNCTF{*************************}" m = libnum.s2n(flag) p = libnum.generate_prime(1024) q = libnum.generate_prime(1024) n = p * q e = 6 c = pow(m, e, n) M = ((m >> 60) << 60) print("n=", n) print("c=", c) print("((m>>60)<<60)=", M) ''' 25300208242652033869357280793502260197802939233346996226883788604545558438230715925485481688339916461848731740856670110424196191302689278983802917678262166845981990182434653654812540700781253868833088711482330886156960638711299829638134615325986782943291329606045839979194068955235982564452293191151071585886524229637518411736363501546694935414687215258794960353854781449161486836502248831218800242916663993123670693362478526606712579426928338181399677807135748947635964798646637084128123883297026488246883131504115767135194084734055003319452874635426942328780711915045004051281014237034453559205703278666394594859431 15389131311613415508844800295995106612022857692638905315980807050073537858857382728502142593301948048526944852089897832340601736781274204934578234672687680891154129252310634024554953799372265540740024915758647812906647109145094613323994058214703558717685930611371268247121960817195616837374076510986260112469914106674815925870074479182677673812235207989739299394932338770220225876070379594440075936962171457771508488819923640530653348409795232033076502186643651814610524674332768511598378284643889355772457510928898105838034556943949348749710675195450422905795881113409243269822988828033666560697512875266617885514107 11941439146252171444944646015445273361862078914338385912062672317789429687879409370001983412365416202240 '''
import Crypto.Util.strxor as xo import libnum, codecs, numpy as np
defisChr(x): iford('a') <= x and x <= ord('z'): returnTrue iford('A') <= x and x <= ord('Z'): returnTrue returnFalse
definfer(index, pos): if msg[index, pos] != 0: return msg[index, pos] = ord(' ') for x inrange(len(c)): if x != index: msg[x][pos] = xo.strxor(c[x], c[index])[pos] ^ ord(' ')
defknow(index, pos, ch): msg[index, pos] = ord(ch) for x inrange(len(c)): if x != index: msg[x][pos] = xo.strxor(c[x], c[index])[pos] ^ ord(ch)
dat = []
defgetSpace(): for index, x inenumerate(c): res = [xo.strxor(x, y) for y in c if x!=y] f = lambda pos: len(list(filter(isChr, [s[pos] for s in res]))) cnt = [f(pos) for pos inrange(len(x))] for pos inrange(len(x)): dat.append((f(pos), index, pos))
c = [codecs.decode(x.strip().encode(), 'hex') for x inopen('Problem.txt', 'r').readlines()]
msg = np.zeros([len(c), len(c[0])], dtype=int)
getSpace()
dat = sorted(dat)[::-1] for w, index, pos in dat: infer(index, pos)